
Mnoho odborníků na datovou analýzu považuje datová centra, datová jezera a datové sklady za vzájemně zaměnitelné alternativy. Každá z těchto struktur má však specifickou roli a jiný primární účel. Zjistěte, jaké jsou mezi nimi rozdíly a proč je pro vaši firmu nejlepší je kombinovat.
Jiná struktura, jiné zaměření
Data jsou stále rozmanitější – stejně jako jejich zdroje a způsoby, jak s nimi nakládat. V byznysu i mimo něj se neustále objevují nové požadavky, pro které tradiční architektura založená na centrálním sběru dat pro předem definované použití již nestačí – nebo alespoň není jediným a nejefektivnějším způsobem.
Výzvou pro lídry v oblasti analýzy dat a architektury je poskytnout moderní infrastrukturu pro správu dat, která podporuje flexibilitu, rozmanitost datových potřeb a konektivitu. To se ale často neobejde bez kombinace různých přístupů k organizaci a zpracování dat. Přesto se někteří stále zaměřují na splnění všech potřeb prostřednictvím jediného architektonického vzoru – a vybírají si mezi tradičním podnikovým skladem, moderním datovým jezerem nebo datovým centrem, jako by šlo o výlučně konkurenční přístupy.
Každá z těchto struktur však může sloužit jiným cílům. Přesto jsou všechny tři klíčové oblasti podnikových investic, takže je důležité se na ně zaměřit a objasnit jejich podobnosti i základní rozdíly.
Datový sklad
Datový sklad je soubor dat, ve kterém lze kombinovat dva nebo více různých zdrojů dat do integrované, časově proměnlivé strategie správy informací. „Slouží tedy primárně ke konsolidaci a vyhodnocování dat, obvykle s pevnou strukturou a daným účelem,“ říká Milan Bartoš, Data Management Manager ve společnosti Trask.
Datové sklady obecně podporují dobře známé, předdefinované a opakovatelné analytické potřeby, které lze škálovat pro mnoho uživatelů v podniku. Nejlépe tak splňují požadavky na střední až vysoce konzistentní sémantiku. Obvykle také podporují poměrně pevnou strategii zpracování (přístup k centrálnímu fyzickému datovému úložišti orientovaný na SQL) a nabízejí vhodné řešení pro složité dotazy, vysokou úroveň souběžnosti a přísné požadavky na výkon. Samy o sobě však neumožňují firmě být agilnější. „ Zjednodušeně řečeno, datové sklady jsou na dlouhou trať, musíte dopředu vědět, jaká data a co po nich budete chtít třeba za rok, “ popisuje Bartoš jednu ze slabin datového skladu.
Datové jezero
Datová jezera shromažďují nezpracovaná data nebo data v jejich nativní podobě s omezenou transformací a zajištěním kvality a události zachycené z různých zdrojových systémů. Obvykle podporují přípravu dat, průzkumnou analýzu a aktivity v oblasti datové vědy – potenciálně napříč širokou škálou předmětů a složek. V důsledku toho také podporují vysoce variabilní sémantiku, obecnou sadu případů analytického použití a různé styly a přístupy zpracování, včetně zjišťování dat, strojového učení a intenzivního dávkového počítání.

“ Jezera prolínají vše dohromady a každý si může vytáhnout to, co právě teď potřebuje. Jsou velmi efektivní ve spotřebě dat, která odpovídají aktuálním přáním lidí ve firmě. Pokud například někdo potřebuje report v daný den, může mít z něj okamžitý výstup,“ zjednodušuje Milan Bartoš. “ V porovnání s datovými sklady však chybí konsolidace. K některým datům se nedostanete, nebo je to velmi pracné. “
Datový rozbočovač
Na rozdíl od datových skladů a datových jezer se datová centra nezaměřují na analytické využití dat. Datové centrum je spíše architektonický vzor, který umožňuje bezproblémový tok dat a správu. Propojuje producenty dat a spotřebitele dat, přičemž používá ovládací prvky správy dat a společné modely, které umožňují efektivní sdílení dat.
Datové uzly se pak zaměřují především na správu konzistentní sémantiky. Mohou podporovat řadu případů použití – nejčastěji provozního charakteru, například poskytování kmenových dat do podnikových aplikací a procesů. Mohou také podporovat řadu strategií zpracování tím, že umožňují výběr technik perzistence dat, stylů integrace a metod přístupu.
Na co myslet při porovnávání skladu, jezera a centra
Datové sklady a datová jezera jsou podobné. Obě struktury poskytují koncový bod pro sběr transakčních podrobných dat, konkrétně pro podporu analytických úloh.
Co to znamená? Že na nich můžete spouštět různé typy analýz, přistupovat k datům, která uchovávají, a podporovat analytické potřeby podniku. Kromě toho mohou jezera a sklady zahrnovat řídicí kontroly, například prostřednictvím monitorování a řešení problémů s kvalitou příchozích dat. Podporují však řízení reaktivnějším a „downstream“ způsobem.
Datové uzly se v porovnání s nimi značně liší, protože obvykle neukládají podrobná data po delší dobu. Neslouží jako úložiště, na kterých se provádějí analytické úkoly, ale jsou to místa pro zprostředkování a sdílení dat. Jednotlivé datové uzly v hubech pak umožňují tok dat v podniku propojením systémů a procesů produkujících data se systémy a procesy, které data spotřebovávají. Datový hub pak lze také použít k připojení podnikových aplikací k datovému skladu nebo datovému jezeru.
Ačkoli optimální použití každé struktury samostatně může být zcela odlišné, rozdíl mezi nimi se může stírat v závislosti na přístupech k návrhu a volbě technologie. Zvlášť, když se oba používají současně. Výsledkem je, že datový sklad, datové jezero a datový rozbočovač lze velmi dobře kombinovat a spolupracovat v efektivní architektuře.
Jak tyto struktury efektivně kombinovat?
Data Hub Centric model
Příkladem efektivního řešení je kombinace, kdy jsou data dodávána do analytických struktur (datových skladů a datových jezer) prostřednictvím datového centra, které funguje jako prostředník a kontrolní bod (viz obrázek níže). Stále více podniků přijímá architekturu datového centra jako ústřední bod pro sdílení a správu všech důležitých dat v celém podniku. To zahrnuje poskytování dat z operačních systémů do analytických struktur, jako jsou datové sklady a datová jezera.
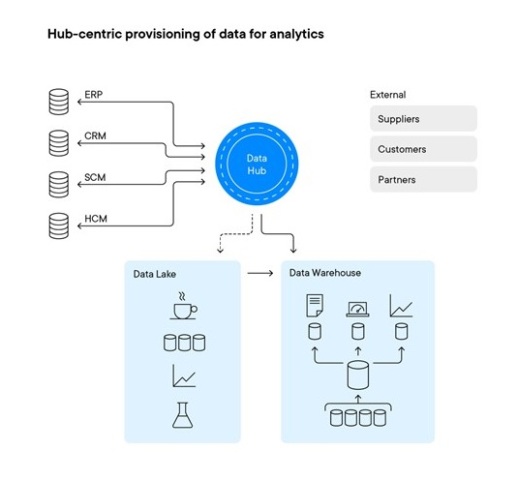
Logický datový sklad lze podporovat prostřednictvím federace dat, která jsou umístěna v datovém jezeře a datovém skladu. Různé charakteristiky datových skladů a datových jezer znamenají, že oba modely jsou stále více vyžadovány pro podporu různorodých analytických potřeb moderního podniku. Kombinace funkcí datového skladu a datového jezera představuje běžný typ logického datového skladu.
Data Lake Centric model
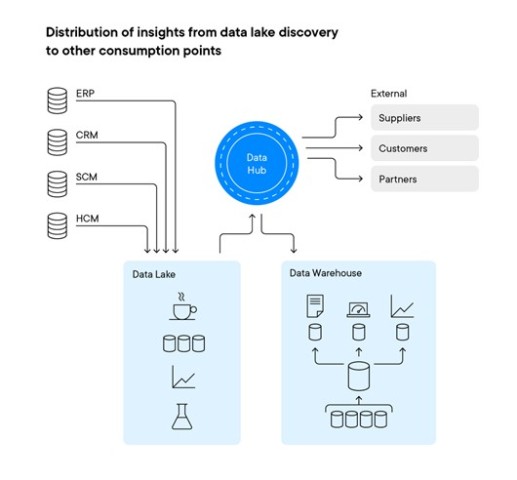
Druhý model zahrnuje umístění datového jezera přímo za zdrojové systémy. Asanalytické úlohy se stávají rozmanitějšími, organizace stále více hledají, jak využít poznatky získané v datovém jezeře a škálovat je pro širší, opakovatelné použití v celém podniku prostřednictvím datového skladu.
Stejně tak roste poptávka po schopnosti poskytovat strukturované analytické výsledky z datového skladu zákazníkům, dodavatelům a dalším. Datové uzly mohou být efektivním místem pro správu a plnění těchto potřeb.
Statistiky získané z operací datového jezera lze poskytnout do datového skladu (pro opakovanou a škálovatelnou spotřebu) a použitá data lze poskytnout přímo z datového jezera externím spotřebitelům prostřednictvím datového centra (viz obrázek níže). Tato data můžeme využít (a zvýšit poskytovanou hodnotu) z různých složek – uvnitř i vně podniku.
Klíčovým prvkem moderní infrastruktury pro správu dat je proto schopnost myslet dynamicky – to znamená schopnost vyvíjet architektonické vzory v průběhu času, umožňovat nová připojení a podporovat nové případy použití. Datové a architektonické týmy by proto podle Milana Bartoše měly požadavky pravidelně přezkoumávat a rozhodovat se, jak na ně reagovat.
Měli byste zvážit následující možnosti:
– Kombinace různých technologií (např. datová jezera a datové sklady) ke shromažďování a analýze dat, aby bylo zajištěno rychlejší zpracování obchodních požadavků.
– Kombinace různých technologických umístění (on-premise a cloud) pro zajištění efektivní správy.
– Použití univerzálních nástrojů pro přenos dat nebo propojení dat.
– Použití dynamického a distribuovaného úložiště dat.
Více informací naleznete na www.trask.cz







